Le tueur de tokens : naviguer dans le code sans le lire
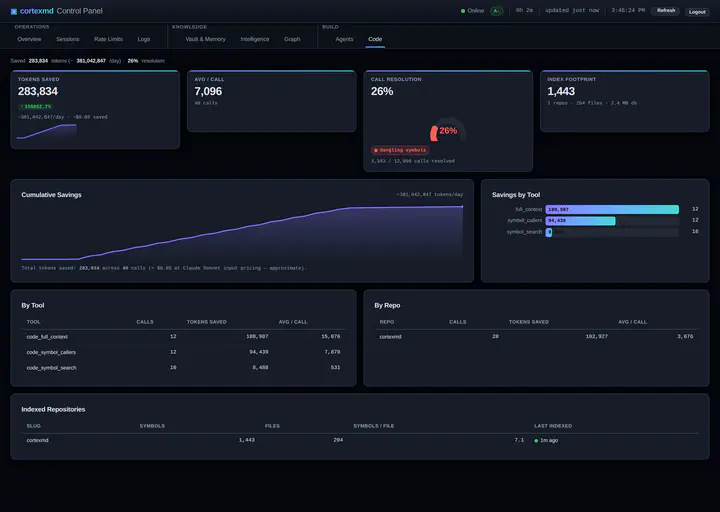
Dans la deuxième partie, j’ai écrit sur la moitié de cortexmd qui combat l’oubli : le moteur de mémoire, avec sa chaleur, sa décroissance et son rêve nocturne. Ce billet parle de l’autre moitié, celle qui combat le gaspillage.
Voici le problème. Quand vous demandez à un agent IA de travailler sur une vraie base de code, le réflexe par défaut est de lire des fichiers. L’agent ouvre un fichier, le tout atterrit dans son contexte, et vous payez désormais pour chacune de ses lignes. La plupart de ces lignes sont du bruit pour la tâche en cours. Vous vouliez savoir ce que fait une fonction et qui l’appelle, et au lieu de cela vous avez acheté un fichier de mille lignes, plus ses imports, plus trois modules d’aide qu’il a tirés au passage par prudence. Faites cela quelques fois et la fenêtre de contexte se remplit de code que l’agent n’utilisera jamais, le signal est enseveli, et la facture est bien réelle.
La solution consiste à arrêter de lire le code pour commencer à l’interroger.
Un dépôt est un graphe, pas un tas de texte
L’intuition est ancienne, ennuyeuse et juste : le code source n’est pas vraiment un tas plat de texte. C’est un graphe de symboles. Des fonctions, des méthodes, des types, et les arêtes entre eux, qui appelle qui. Un IDE le sait. “Aller à la définition” et “trouver toutes les références” ne lisent pas vos fichiers de haut en bas à chaque clic. Ils consultent un index. cortexmd donne la même chose à un agent.
L’indexeur est un binaire Rust (cortexmd-cli, le même binaire qui embarque le client en ligne de commande et les hooks de session dont je parlerai plus loin). Il parcourt un dépôt, analyse chaque fichier avec tree-sitter, et écrit le résultat dans une base de données de symboles SQLite. Pour chaque symbole, il enregistre le nom, le genre (fonction, méthode, type, et ainsi de suite), la signature, la docstring s’il y en a une, la plage dans le fichier, et, point crucial, le graphe d’appels : les appelants et les appelés. tree-sitter est le bon outil ici parce qu’il est rapide, incrémental, et qu’il parle beaucoup de langages, si bien que la même passe d’indexation fonctionne sur un dépôt polyglotte au lieu d’exiger un parseur sur mesure par chaîne d’outils.
Une fois cette base de données en place, l’agent n’a plus jamais besoin d’ouvrir un fichier juste pour se repérer.
Les outils de navigation de code
L’index est exposé aux clients MCP sous la forme d’un ensemble d’outils peu coûteux. Chacun répond à une question précise qu’un agent se pose réellement pendant qu’il travaille :
- recherche de symboles : trouver des symboles par nom, signature, ou texte de docstring. Le point d’entrée vers tout le reste.
- plan de fichier : la forme d’un fichier (ses symboles et leurs signatures) sans les corps. Vous obtenez la table des matières plutôt que le livre.
- récupérer un symbole : extraire le corps d’exactement un symbole quand vous avez décidé que vous en aviez besoin, et rien d’autre.
- appelants et appelés : parcourir le graphe d’appels dans un sens ou dans l’autre. Qui appelle ceci, et ce que ceci appelle.
- impact d’un changement : la réponse transitive à “si je modifie ceci, qui casse ?”. C’est celui que je dégaine le plus souvent avant de toucher à quoi que ce soit de porteur.
- chaîne d’appels : le chemin d’un symbole à un autre, pour voir comment A atteint réellement Z.
- détection de code mort : les symboles vers lesquels rien ne pointe.
- détection de cycles d’imports : là où le graphe de modules boucle sur lui-même.
- détection de doublons sémantiques : la détection de copier-coller, les corps quasi identiques qui ont divergé.
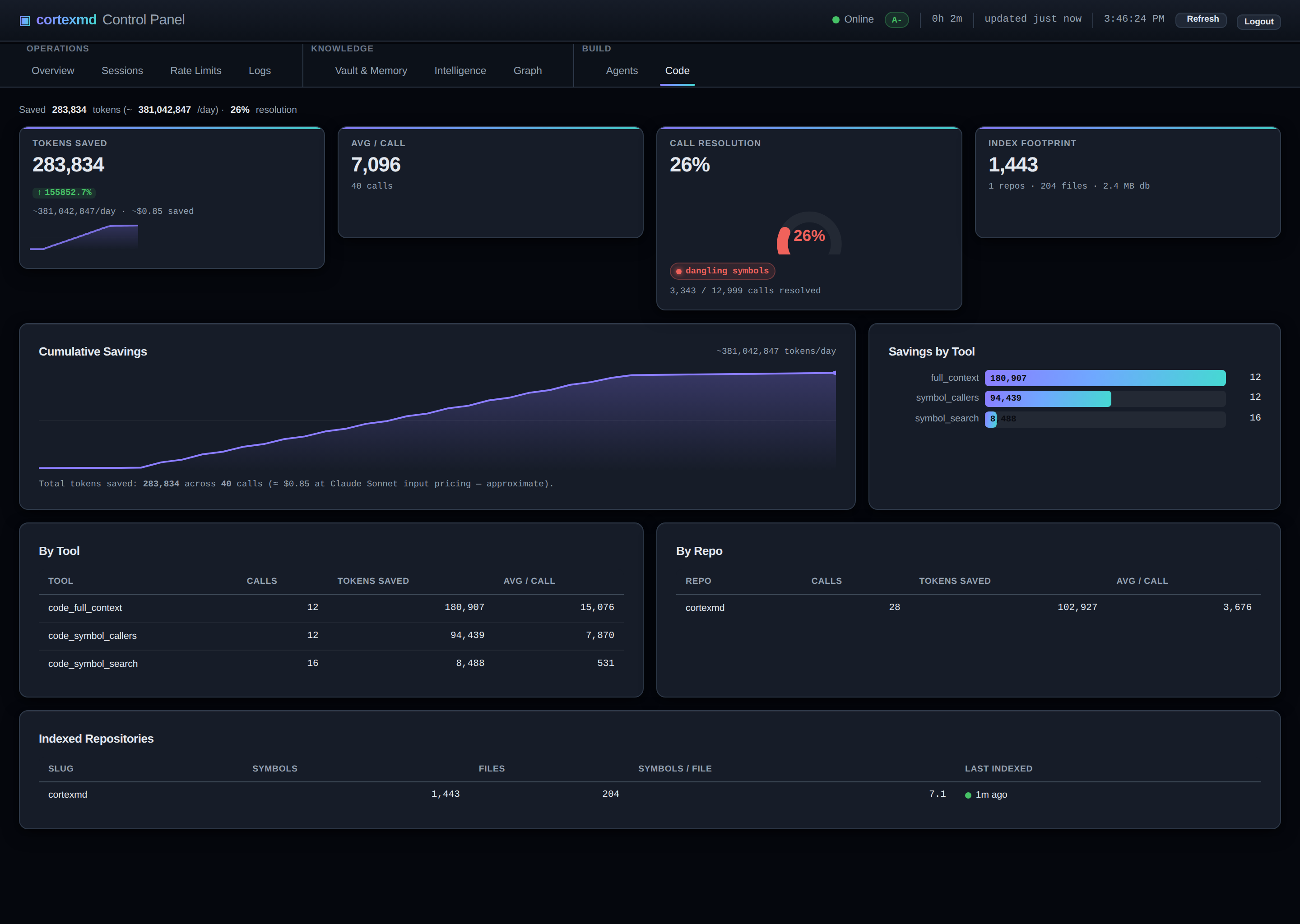
Le motif est le même pour tous. L’agent restreint avant de lire. Rechercher pour trouver le symbole, dresser le plan pour voir le voisinage, consulter les appelants et l’impact d’un changement pour comprendre le rayon d’explosion, et seulement ensuite, s’il en a vraiment besoin, récupérer un symbole. La plupart des tâches n’exigent jamais un fichier complet.
Environ 60 tokens par résultat
Voici l’objectif de conception qui a guidé tout cela. Une recherche de navigation de code est censée coûter environ 60 tokens par résultat. Lire un fichier entier en coûte des milliers. Interroger l’index est donc censé revenir bien moins cher que lire, pour la même réponse utile.
Je veux être honnête sur ce qu’est ce chiffre et ce qu’il n’est pas. C’est une cible que j’ai visée en concevant l’outil, pas un résultat de référence que je vous cite. Le coût exact dépend du symbole, du langage, de la quantité de docstring. Mais sa forme générale est tout l’enjeu : un résultat est un enregistrement compact (nom, genre, signature, une plage, quelques arêtes), pas un pavé de code source. Quand l’unité de travail est un fait de 60 tokens au lieu d’un fichier de 2 000 tokens, un agent peut poser vingt questions pour le prix d’une lecture, et la fenêtre de contexte reste pleine de réponses au lieu de meule de foin.
Cela se lit aussi mieux pour le modèle. Une liste propre d’appelants est plus facile à raisonner que la même information étalée sur cinq fichiers que l’agent a dû charger pour la reconstituer.
Attraper la vieille habitude
Il y a un piège à donner de meilleurs outils à un agent : il doit penser à les utiliser. La mémoire musculaire d’“enquêter sur le code”, c’est grep, cat, head, tail. Ces habitudes sont profondes, et un agent y retombera volontiers et se mettra à charger des fichiers dans son contexte dès que vous cessez de surveiller.
Alors cortexmd embarque un hook shell optionnel. Quand il est activé et que vous travaillez dans un dépôt indexé, il réécrit ces commandes en leurs équivalents peu coûteux de navigation de code. Un grep cherchant un symbole devient une recherche de symboles. Un cat d’un fichier devient un plan de fichier. L’agent croit faire la vieille chose, et l’index répond discrètement à la place. C’est optionnel à dessein, parce que réécrire les commandes shell de quelqu’un est exactement le genre de magie à laquelle on veut consentir plutôt que la découvrir, et parce que la réécriture n’a de sens que sur un dépôt réellement indexé.
La belle propriété, c’est qu’il rejoint l’agent là où ses habitudes sont déjà. Vous n’avez pas à rééduquer le réflexe, vous l’interceptez simplement.
Le dogfooding sur son propre code source
Je n’ai pas testé cela sur un jouet. cortexmd est un monorepo polyglotte (TypeScript d’un côté, Rust de l’autre, j’y reviens dans la quatrième partie), et j’ai pointé l’indexeur sur le code source du projet lui-même pour travailler dessus à travers ses propres outils de navigation. C’est le test qui compte. Quand vous modifiez l’indexeur tout en naviguant avec l’indexeur, les aspérités vous trouvent vite. “L’impact d’un changement dit que rien ne casse, alors pourquoi ça a cassé” est une phrase très motivante à lire dans ses propres journaux.
Le dogfooding est aussi l’endroit où les deux moitiés de cortexmd se rencontrent. L’index de code dit à l’agent ce qu’est le code en ce moment. Le moteur de mémoire de la deuxième partie lui dit pourquoi le code est ce qu’il est, les décisions et les impasses qu’aucune base de données de symboles n’enregistrera jamais. La structure plus l’histoire. L’une s’interroge, l’autre se rappelle, et ensemble elles forment l’essentiel de ce que je veux qu’un collaborateur possède.
C’est encore une pré-alpha, donc les noms exacts des outils et la configuration vont bouger. L’idée sous-jacente est stable : naviguer dans le code en interrogeant un index, pas en lisant des fichiers, et payer 60 tokens pour un fait plutôt que des milliers pour une meule de foin.
Dans la quatrième partie, j’aborde la partie qui a transformé un outil privé de homelab en quelque chose que je pouvais mettre sur internet : pourquoi un outil entièrement réglé sur ma propre installation ne pouvait pas être partagé tel quel, la refonte autour du brain-vault qui l’a généralisé, et pourquoi je l’ai passé en open source.
La page du projet est ici, et le code se trouve sur github.com/Leicas/cortexmd.
Série
- Donner un second cerveau à un agent IA
- Le moteur de mémoire : chaleur, décroissance et rêves
- Le tueur de tokens : naviguer dans le code sans le lire (vous êtes ici)
- Ouvrir le cerveau : le modèle brain-vault
Antoine Weill--Duflos
Responsable Technologie et Applications
Je m’intéresse à l’haptique, la mécatronique, la micro-robotique…