Donner un second cerveau à un agent IA
Je travaille avec un agent de programmation presque tous les jours maintenant. Il est vraiment bon. Il lit mon code, raisonne dessus, propose des changements, lance les tests, répare ce qu’il a cassé. Et chaque fois que j’ouvre une nouvelle session, il a la mémoire d’un poisson rouge.
Il ne se souvient pas de la décision que nous avons prise la semaine dernière sur la raison pour laquelle un module est structuré comme il l’est. Il ne se souvient pas que je préfère les virgules aux tirets, ni qu’un coin du code est porteur et fragile. Il ne se souvient pas de la conversation où nous avions écarté une approche pour de bonnes raisons. Tout ce contexte vivait dans la session précédente, et la session précédente n’existe plus. Alors je réexplique. Puis je réexplique encore le lendemain.
Voilà le premier problème. L’agent oublie.
Et il n’y a pas que le code. Dès que je lui demande de l’aide pour quoi que ce soit d’humain, le même trou s’ouvre. Demandez-lui de rédiger un e-mail et il n’a aucune idée de qui est le destinataire pour moi, s’il s’agit d’un ami proche, d’un collègue ou d’un partenaire avec qui je dois faire attention, et donc il ne sait pas quel ton adopter, parce que ce ton vivait dans des conversations passées qu’il ne peut plus voir. Il fait un mauvais travail pour relier une session à la suivante, si bien que chaque fil repart à froid. Et la façon dont je cloisonne ma vie aggrave les choses : le personnel dans un compte, le professionnel dans un autre, comme la plupart des gens. Dès que je passe de l’un à l’autre, tout ce que l’agent avait appris sur moi a tout simplement disparu. Pouf. Plus de mémoire.
Deux problèmes, pas un seul
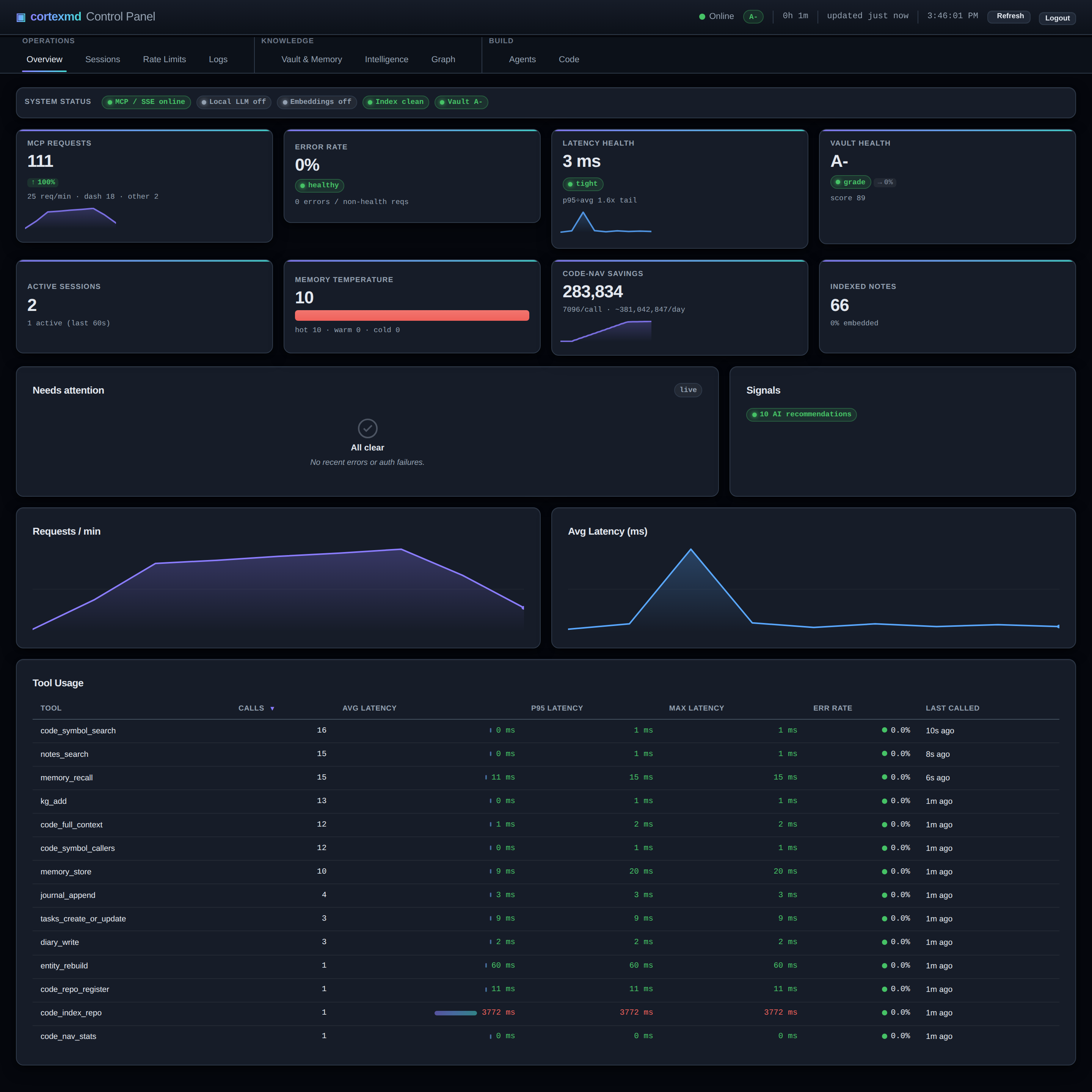
Le second problème est plus discret, mais il apparaît sur chaque facture. Pour faire quoi que ce soit d’utile, l’agent doit comprendre le code, et la façon dont il comprend le code, c’est en le lisant. Donc il lit des fichiers. Des fichiers entiers. Pour répondre à une petite question sur une fonction, il va charger un module entier dans son contexte, et souvent les modules qui appellent ce module aussi. Multipliez cela sur une session de travail et vous payez, en tokens, pour charger le même code source encore et encore, dont la majeure partie n’a rien à voir avec la question posée.
Les deux problèmes viennent du même endroit : l’agent n’a aucun stockage persistant de ce qu’il a appris, et aucun moyen bon marché de consulter les choses. Il n’a que la fenêtre de contexte devant lui, et cette fenêtre est à la fois oublieuse et coûteuse à remplir.
J’ai décidé de m’attaquer aux deux. Pas parce que j’avais une idée de produit, mais parce que ça m’agaçait au quotidien et que j’avais un homelab qui ne demandait qu’à être utile.
Il y avait aussi une raison personnelle qui rendait la forme de la solution évidente. Il y a quelque temps, après avoir lu le long récit d’un ami sur son propre parcours de gestion de connaissances personnelles, je me suis mis à prendre des notes dans Obsidian. Construire ce second cerveau pour moi-même a changé ma façon de voir le problème. Si un coffre de notes liées fonctionne comme mémoire externe pour moi, il devrait fonctionner comme mémoire externe pour l’agent aussi. Je pouvais le laisser lire le mien pour démarrer, en lecture seule, puis le laisser construire le sien, un cerveau que je pourrais réellement ouvrir, parcourir et comprendre. Pas une boîte noire d’embeddings quelque part, mais des notes, dans un coffre, qui m’appartiennent.
L’origine sur le homelab
Depuis un moment, je fais tourner un petit serveur MCP sur mon homelab. MCP, le Model Context Protocol, est la manière standard de donner à un client IA des outils et des données qu’il peut aller chercher. Le serveur que j’avais construit s’appelait obsidian-mcp, et son premier rôle était simple : donner à Claude la capacité de lire, de chercher et d’écrire des notes dans mon coffre Obsidian.
Il tournait dans un conteneur Docker derrière un reverse proxy, mes notes étaient déjà là, et tout à coup l’agent pouvait y accéder. Cela seul était déjà utile. Mais cela transformait aussi le coffre en un endroit naturel où placer les réponses à mes deux problèmes, parce qu’un coffre n’est que du texte structuré qu’un agent peut lire et écrire, et c’est exactement ce sur quoi une mémoire et un index de code doivent reposer.
Le serveur a donc fait pousser deux nouvelles capacités, une pour chaque problème.
La première capacité est un système de mémoire, inspiré de mempalace, un projet de palais de mémoire pour agents IA. Au lieu de laisser tout s’évaporer à la fin d’une session, l’agent peut stocker ce qu’il apprend : une observation, une décision, une intuition, une préférence que j’ai exprimée à voix haute. Ces mémoires ne s’empilent pas simplement à l’infini dans une liste plate. Elles ont un cycle de vie. Celles qui servent restent chaudes et faciles à faire remonter, celles que personne ne touche refroidissent et finissent par être pliées dans des résumés, et au début d’une nouvelle session l’agent fait un réveil qui ramène à la surface les mémoires les plus chaudes et les plus pertinentes. L’objectif, c’est la continuité. L’agent reprend à peu près là où il s’était arrêté plutôt qu’à partir de zéro. C’est le sujet de la deuxième partie.
La seconde capacité est un index de code. Plutôt que de lire des fichiers entiers pour comprendre un dépôt, l’agent interroge un index de celui-ci. Un indexeur en Rust parcourt le dépôt, l’analyse et enregistre les choses que l’on veut réellement consulter : quels symboles existent, leurs signatures, où ils vivent, et surtout qui appelle qui. Ensuite l’agent pose des questions ciblées. À quoi ressemble cette fonction ? Qui l’appelle ? Qu’est-ce qui casse si je la modifie ? Chaque réponse est petite et bon marché, de l’ordre d’une consultation plutôt que d’une lecture complète, au lieu de traîner le fichier entier dans le contexte. L’objectif de conception est franc : une consultation de navigation de code devrait coûter environ soixante tokens par résultat et être bien moins chère que la lecture du fichier dont elle provient. C’est le sujet de la troisième partie.
D’un outil privé à cortexmd
Pendant des mois, ce fut une affaire personnelle. Ça tournait sur mon matériel, sur mon propre coffre Obsidian privé, celui qui contient à la fois des notes personnelles et professionnelles. Je n’en citerai rien ici, et l’outil lui-même est délibérément construit pour que les données restent les miennes. Mais le constat tient : c’était un outil que j’avais fait pour moi, et je l’utilisais tous les jours.
Puis je me suis heurté à un autre genre de mur, qui venait précisément de la façon dont il marchait bien pour moi. Je le raconterai correctement dans la quatrième partie, mais en résumé : tout était réglé sur ma propre installation, mon coffre, monté et synchronisé à ma façon, ce qui en faisait un excellent outil personnel et le rendait impossible à faire tourner pour quiconque d’autre. Le rendre partageable impliquait une refonte, et c’est cette refonte qui en a finalement fait quelque chose que d’autres pouvaient utiliser.
Cette refonte est devenue cortexmd. C’est open source, sous licence MIT, et public sur github.com/Leicas/cortexmd. C’est honnêtement en pré-alpha. Les API et les noms de configuration sont encore en mouvement, et je ne miserais pas un workflow de production dessus pour l’instant. Le cadrage honnête est le bon : j’ai construit ça pour moi, puis je l’ai nettoyé pour le partager. Le nettoyage est un vrai travail et il constitue l’essentiel de la quatrième partie.
Voilà donc la forme de la série. Il y avait deux problèmes, un agent qui oublie et un agent qui brûle des tokens à relire du code. Il y a deux réponses, un système de mémoire et un index de code, tous deux nés à l’intérieur d’un serveur MCP sur un homelab. Et il y a la refonte qui a transformé un outil privé en quelque chose que vous pouvez faire tourner vous-même.
Ce qui arrive
- Partie 2, le moteur de mémoire. Chaleur, déclin et rêves. Les huit catégories dans lesquelles une mémoire peut tomber, le cycle de vie chaud vers tiède vers froid, la promotion à l’accès, la consolidation, le rappel hybride qui fusionne recherche plein texte et recherche sémantique, le réveil de session, et le graphe de liaison automatique qui relie les notes entre elles au fur et à mesure qu’elles sont stockées.
- Partie 3, le tueur de tokens. L’indexeur en Rust et tree-sitter, la base de données de symboles SQLite, les outils de navigation de code, l’idée des environ soixante tokens par résultat, le hook shell optionnel qui réécrit des commandes comme grep et cat sur un dépôt indexé en leur équivalent bon marché, et ce que ça a donné de l’utiliser sur le propre code source du projet.
- Partie 4, l’ouverture du cerveau en open source. Pourquoi un outil qui ne marchait que pour moi a dû être repensé pour être partagé, le modèle du brain-vault qui le généralise, les deux modes de déploiement, le monorepo polyglotte tenu ensemble par un contrat partagé, le renommage, et pourquoi je tiens à posséder mes propres données.
Si vous voulez sauter directement au code, la page du projet est par ici et le dépôt est sur GitHub. Sinon, la deuxième partie est l’endroit où l’agent commence à se souvenir.
Série
Ceci est la Partie 1 : Donner un second cerveau à un agent IA (vous êtes ici).
- Partie 1 : Donner un second cerveau à un agent IA (ce billet)
- Partie 2 : Le moteur de mémoire : chaleur, déclin et rêves
- Partie 3 : Le tueur de tokens : naviguer dans le code sans le lire
- Partie 4 : Ouvrir le cerveau en open source : le modèle brain-vault
Page du projet : cortexmd. Source : github.com/Leicas/cortexmd.
Antoine Weill--Duflos
Responsable Technologie et Applications
Je m’intéresse à l’haptique, la mécatronique, la micro-robotique…