Ouvrir le code du cerveau : le modèle du brain-vault
Dans la partie 3 j’ai décrit le volet navigation de code de cette chose : un indexeur Rust qui parcourt un dépôt, construit une base de données de symboles, et permet à un agent d’interroger la structure du code pour à peu près le coût d’un simple grep au lieu de lire des fichiers entiers. Cela, plus le moteur de mémoire de la partie 2, constituait l’outil privé que je faisais tourner sur mon homelab depuis quelques mois. Ça marchait. Je l’utilisais tous les jours.
Mais il avait une limite inscrite dans ses fondations, et cette limite est la raison d’être de ce billet.
Le problème : il ne marchait que pour moi
La version privée, celle qui s’appelait encore obsidian-mcp à l’époque, était entièrement façonnée autour de mon installation. Elle lisait mon coffre Obsidian personnel, celui que je garde synchronisé entre mes machines et que je traite comme la source de vérité pour tout ce que je fais. Ses conventions, ses chemins, la façon dont elle découvrait et indexait les notes, tout supposait mon environnement, ma structure, mes habitudes. Au quotidien, c’était invisible. C’était un outil vraiment bon, et il s’améliorait à mesure que je m’appuyais dessus.
L’ennui, c’est qu’il était bon pour moi d’une façon qui le rendait impossible à confier à quelqu’un d’autre. Vous ne pouviez pas simplement le pointer sur vos propres notes et le voir fonctionner. Il attendait mon coffre, monté comme je le monte, synchronisé comme je le synchronise. Il lisait depuis un espace réglé pour exactement une personne, et cette personne, c’était moi. Comme outil personnel, c’était parfait. Comme projet à passer en open source, c’était une impasse, car la première chose sur laquelle tomberait tout autre utilisateur, c’est que toute la conception supposait discrètement qu’il était moi.
La question qui a guidé la refonte n’était donc pas comment corriger un bug. Elle était plus simple et plus exigeante : que faudrait-il pour qu’une personne qui n’est pas moi fasse tourner ceci sur ses propres notes, en toute sécurité, sans hériter de mon installation ? Y répondre honnêtement voulait dire séparer deux choses que la version privée avait emmêlées, les notes que je lis et les données que l’outil écrit.
La refonte : le modèle du brain-vault
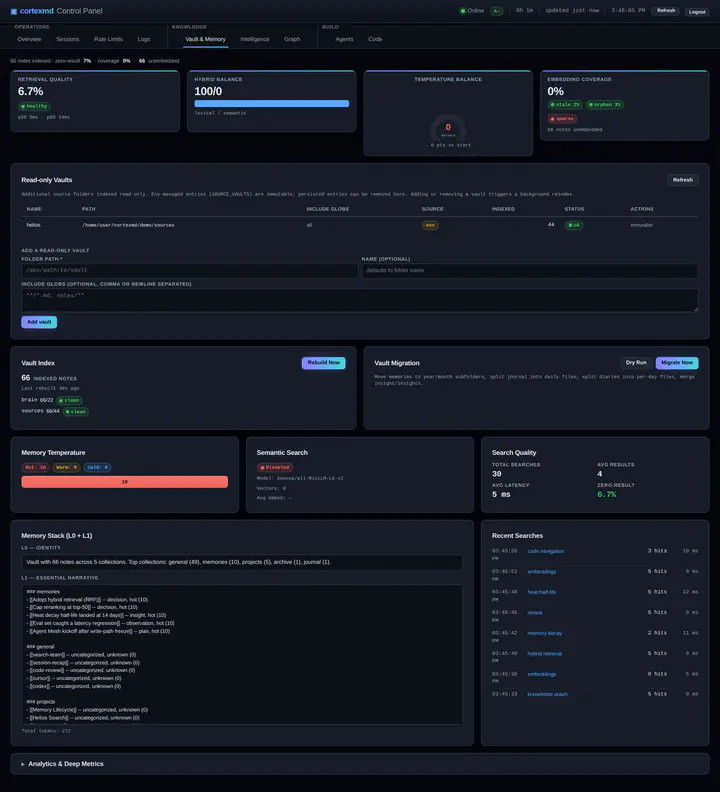
Le correctif qui a rendu cortexmd partageable est presque embarrassant de simplicité une fois qu’on s’est brûlé. cortexmd possède son propre brain vault séparé, et ce brain vault est la seule chose dans laquelle il a le droit d’écrire. Mémoires, journal, journaux d’agents, tâches, notes du graphe de connaissances, la liste des dépôts de code indexés : tout cela vit dans le brain vault, et cortexmd en est l’unique rédacteur.
Vos propres coffres, ceux que vous modifiez à la main dans Obsidian, sont attachés en tant que coffres sources en lecture seule. cortexmd les indexe pour la recherche et la navigation de code, et il ne les modifie jamais. Pas une mise à jour de chaleur, pas une étiquette, pas un seul octet. Attacher un coffre source se fait sur option, avec une liste d’autorisation qui refuse par défaut, de sorte que vous pouvez garder des sous-arbres privés entièrement hors de l’index et n’exposer que les parties que vous voulez que l’agent voie.
Les données circulent dans un seul sens. Les coffres sources entrent, le brain vault sort, et les deux ne se chevauchent jamais. Vous attachez le coffre qui est le vôtre, l’outil le lit et n’y réécrit rien, et le cerveau qu’il construit vit entièrement ailleurs. C’est ce qui le rend général : il n’y a plus aucune supposition que le coffre soit le mien, monté à ma façon, ou synchronisé à ma façon. C’est aussi ce qui le rend sûr, car un outil qui n’écrit jamais dans vos notes ne peut pas les écraser, et il n’y a aucun fichier partagé qu’un agent de synchronisation puisse bifurquer. Le couplage qui maintenait la version privée collée à ma machine a tout simplement disparu.
SOURCE_VAULTS[] (read-only, opt-in, allowlisted)
┌───────────┐ ┌───────────┐ ┌───────────┐
│ notes/ │ │ code/ │ │ docs/ │
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ index (one-way, read) │
└──────────────┼──────────────┘
▼
┌──────────────────┐
│ cortexmd │ <- sole writer
│ (MCP server) │
└────────┬─────────┘
│ writes
▼
┌──────────────────┐
│ BRAIN_VAULT │ memories · journal · diaries
│ (own dir, not │ tasks · KG notes · code-repos.json
│ your vault) │
└──────────────────┘
Le brain vault par défaut est un répertoire de données dédié, quelque chose comme ~/.local/share/cortexmd/brain, jamais votre véritable coffre Obsidian. Vous pouvez le pointer ailleurs, mais le défaut garde les écritures de l’outil et vos notes dans deux endroits clairement séparés dès la première exécution.
Deux façons de le faire tourner
Une fois que l’histoire de l’écriture était saine, l’histoire du déploiement devait suivre. cortexmd se livre avec deux modes, et ils sont d’égale importance plutôt qu’un vrai et un de jouet.
Le défaut recommandé pour une seule personne est local-stdio. Il tourne sur votre propre machine, parle MCP via stdio avec n’importe quel client que vous utilisez, et lit vos coffres directement depuis le disque. Pas de synchronisation. Pas de Docker. Pas d’authentification. Aucun réseau du tout. Pour une personne sur une machine c’est tout ce dont vous avez besoin, et c’est le mode vers lequel j’orienterais presque tout le monde en premier. Tout l’intérêt de la refonte était qu’un seul utilisateur puisse obtenir le cerveau complet sans aucun du poids opérationnel que la version privée avait fini par accumuler autour d’elle.
Le second mode est l’auto-hébergement HTTP, et c’est explicitement la voie avancée. Ici cortexmd tourne comme un serveur Express avec une authentification en bonne et due forme (clé d’API ou OAuth2), et les coffres sources sont tirés en lecture seule via un transport. Ce transport est une interface que j’ai appelée la couture IVault, avec des implémentations pour le disque local, git-pull, WebDAV et S3. C’est le mode pour les configurations multi-clients ou véritablement distantes, où plusieurs clients MCP partagent un cerveau ou bien les données sources vivent ailleurs que sur le disque du serveur lui-même. Cela représente plus de pièces mobiles, et vous n’y avez recours que lorsque vous en avez réellement besoin.
L’important, c’est que les deux modes partagent le même modèle source-en-lecture-seule, cerveau-rédacteur-unique. Le mode HTTP conserve la même garantie : vos sources restent en lecture seule et le cerveau est la seule cible d’écriture. Il change seulement la façon dont les sources en lecture seule parviennent à l’indexeur.
Un monorepo polyglotte tenu ensemble par un contrat
L’autre chose que l’ouverture du code m’a forcé à nettoyer, c’est la couture entre les deux langages dont ce projet est fait, car ce sont vraiment deux projets portant un seul manteau.
packages/server est le serveur MCP en TypeScript : Node 22, Express, le moteur de mémoire, la logique de rappel, les définitions d’outils qui apparaissent aux clients sous l’espace de noms mcp__cortexmd__. crates/cli est un unique binaire Rust, cortexmd-cli, qui est l’indexeur tree-sitter plus le client en ligne de commande, les crochets de session, et le HUD de la barre d’état. Deux chaînes d’outils, collées ensemble par la CI.
La partie difficile d’une scission comme celle-ci, c’est l’endroit où elles doivent s’accorder exactement. Les identifiants de symboles que l’indexeur Rust produit doivent être identiques octet pour octet à ceux que le côté TypeScript attend, sinon toute la couche de navigation de code pointe silencieusement vers rien. Il y a donc un répertoire contract/ qui contient le format de fil partagé, la spécification des identifiants de symboles, et un jeu de golden fixtures. Une vérification de parité en CI fait passer les mêmes entrées à travers les deux côtés et fait échouer la compilation si le producteur Rust et le consommateur TypeScript sont un jour en désaccord sur ce que devrait être un identifiant. Le contrat est l’arbitre, et il garde les deux langages honnêtes sans qu’aucun n’ait à faire confiance à l’autre.
Le changement de nom, et ce que c’est maintenant
Quand j’ai rassemblé tout cela pour le partager, l’ancien nom ne convenait plus. obsidian-mcp décrivait ce que c’était au départ : un pont vers le coffre d’une seule application. Ce que c’était devenu, c’était un cerveau de mémoire et de navigation de code qui utilisait par hasard le markdown de style Obsidian comme un format de stockage parmi d’autres. Alors c’est devenu cortexmd, et c’est le nom sous lequel il se livre.
Une note d’honnêteté : ceci est en pré-alpha. C’est public et sous licence MIT à github.com/Leicas/cortexmd, et les noms de configuration ainsi qu’une partie des API sont encore mouvants. Je l’ai construit pour moi d’abord, l’ai fait tourner sur mon propre homelab au-dessus de mon propre coffre privé de notes personnelles et professionnelles, j’ai réalisé qu’il était câblé trop étroitement sur ma propre installation pour être partagé, je l’ai généralisé, puis je l’ai nettoyé suffisamment pour le mettre là où d’autres personnes peuvent l’utiliser. Ce n’est pas un produit fini et je ne prétends pas que c’en est un.
Ce dont je me sens bien, c’est de sa forme. Vos notes restent les vôtres, sur votre disque, en lecture seule, avec les parties privées exclues par défaut. Le cerveau que l’agent construit vit dans son propre endroit et ne va jamais retoucher vos fichiers. Dans le mode par défaut rien ne quitte votre machine : pas de cloud, pas de compte, pas de réseau. C’est la version local-first, propriétaire-de-vos-données de l’idée que je voulais vraiment depuis le début, et il a fallu la détacher de ma propre installation pour y arriver.
Si quoi que ce soit de tout cela vous est utile, la page du projet a la vue d’ensemble et les liens : cortexmd. Et si vous voulez le lire depuis le début, la partie 1 est l’endroit où la série commence.
Série
Ceci est la partie 4 d’une série en quatre parties sur cortexmd.
- Partie 1 : Donner un second cerveau à un agent IA
- Partie 2 : Le moteur de mémoire : chaleur, déclin et rêves
- Partie 3 : Le tueur de tokens : naviguer dans le code sans le lire
- Partie 4 : Ouvrir le code du cerveau : le modèle du brain-vault (vous êtes ici)
Antoine Weill--Duflos
Responsable Technologie et Applications
Je m’intéresse à l’haptique, la mécatronique, la micro-robotique…