Le moteur de mémoire : chaleur, déclin et rêves
Dans la première partie j’ai décrit deux problèmes qui revenaient sans cesse me mordre quand je travaillais avec des agents IA. Le premier, c’est qu’ils oublient tout entre les sessions. Le second, c’est qu’ils brûlent des tokens à relire du code qu’ils ont déjà vu. Ce billet porte sur le premier problème, et sur la partie de cortexmd à laquelle je tiens le plus : le moteur de mémoire. L’approche d’ensemble est inspirée de mempalace, un projet de palais de mémoire pour agents IA ; ce qui suit, c’est la façon dont cortexmd en construit sa propre version.
La solution naïve à l’oubli, c’est de tout déverser dans le contexte. Garder un gros fichier de notes, le coller au début de chaque session et espérer que l’agent le lise. J’ai essayé des variantes de ça, et ça s’effondre vite. Le fichier grossit sans limite. Des faits anciens et périmés voisinent avec la seule chose qui compte vraiment aujourd’hui, sur un pied d’égalité. Vous payez pour toute la pile à chaque tour, et le signal qui vous intéresse se retrouve enseveli sous du bruit dont vous avez cessé de vous soucier depuis longtemps. Une mémoire humaine ne fonctionne pas comme ça, et elle ne le devrait pas. L’objectif de conception était donc simple à énoncer mais plus difficile à construire : l’agent devrait se souvenir comme le fait une personne, où ce que vous utilisez reste vif et ce que vous cessez de toucher s’estompe.
Huit sortes de mémoire
Quand un agent stocke quelque chose, cortexmd ne le traite pas comme un bloc de texte indifférencié. Chaque souvenir est auto-catégorisé dans l’une de huit sortes : observation, décision, idée, conversation, fait, préférence, plan et réflexion. La distinction compte parce que ces choses se comportent différemment dans le temps et veulent être retrouvées différemment. Une préférence (je veux toujours l’orthographe britannique, je déteste les tirets cadratins) est un fait durable sur ma façon de travailler, et elle devrait continuer à remonter. Un fragment de conversation est contextuel et surtout utile peu après qu’il s’est produit. Une décision est quelque chose que vous voulez pouvoir retrouver des mois plus tard quand vous vous demandez pourquoi diable vous avez fait ça. Étiqueter la sorte dès le départ donne au reste du système quelque chose à partir de quoi raisonner, au lieu de forcer chaque étape ultérieure à deviner à partir du texte brut.
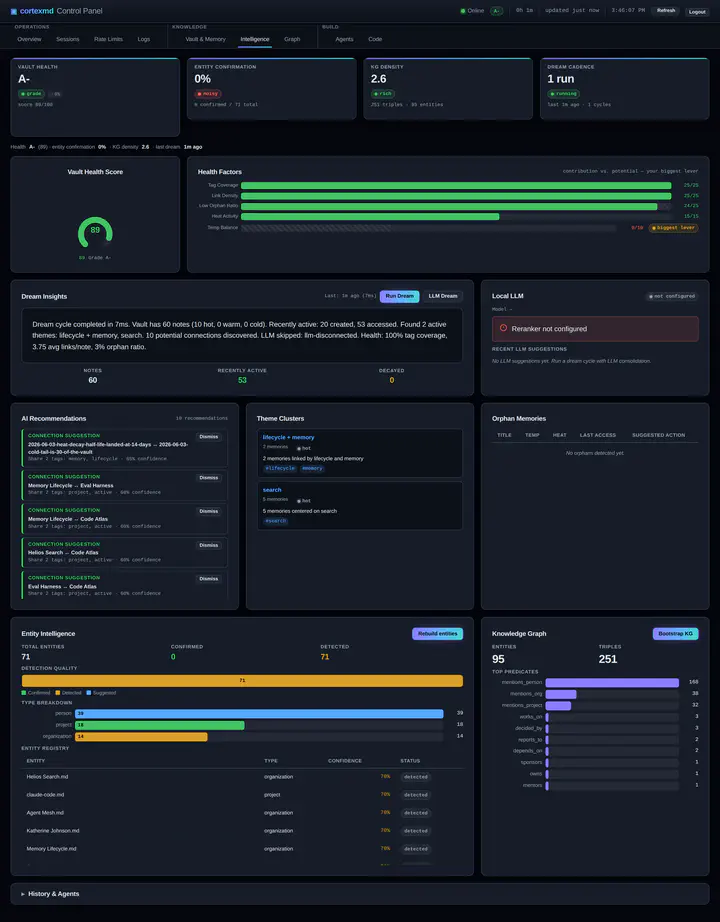
Chaleur : chaud, tiède, froid
L’idée centrale est que chaque souvenir a une température, et que la température décline. Un souvenir frais ou récemment utilisé est chaud. Laissez-le intact et il refroidit vers tiède, puis après environ un mois d’inactivité il dérive vers froid, et les souvenirs plus froids finissent par être archivés plutôt que gardés au premier plan de l’esprit de l’agent.
Le détail crucial, c’est la promotion à l’accès : lire un souvenir le réchauffe. C’est toute l’astuce. Vous n’avez pas à curer manuellement ce qui est important. L’importance se révèle par l’usage. Les souvenirs vers lesquels vous et l’agent revenez sans cesse restent chauds précisément parce que vous revenez sans cesse vers eux, et ceux que vous ne touchez jamais coulent d’eux-mêmes. C’est le même instinct qu’un cache de type least-recently-used, sauf que ce qui est mis en cache, c’est le sens qu’a l’agent de ce qui compte en ce moment, et l’éviction est gracieuse : froid puis archivé, pas supprimé.
Pourquoi se donner tout ce mal au lieu d’un seul stock plat ? Parce que la température donne au rappel un a priori. Quand l’agent part chercher quelque chose, il ne fait pas face à une mer plate de notes également plausibles. Il a un sens intégré de ce qui a été actif récemment, et ce signal ne coûte rien de plus à maintenir parce qu’il découle de l’usage normal.
Consolidation : ranger le tiroir des froids
Laisser les souvenirs refroidir n’est que la moitié de l’histoire. Si vous laissez simplement les souvenirs froids s’empiler, vous vous retrouvez avec un tiroir plein de bouts quasi dupliqués : cinq notes légèrement différentes sur la même tâche terminée depuis longtemps, chacune un peu périmée, aucune ne valant la peine d’être lue seule. Alors cortexmd consolide. Les souvenirs froids apparentés sont repliés ensemble en résumés, de sorte que l’essentiel survive en un endroit cohérent tandis que les fragments redondants cessent d’encombrer. Le détail n’est pas jeté à la légère, il est compressé en quelque chose que vous voudriez réellement lire plus tard. Le refroidissement décide de ce qui n’est plus urgent ; la consolidation décide quoi en faire.
Rappel hybride
Bien stocker la mémoire ne sert à rien si vous ne pouvez pas la récupérer. Le rappel dans cortexmd est hybride. Il lance une recherche lexicale en texte intégral (la correspondance par mots-clés, bonne pour les termes et noms exacts) et la fusionne avec une recherche sémantique sur des embeddings (la correspondance par le sens, bonne quand vous vous souvenez de l’idée mais pas des mots). Le lexical seul rate tout ce qui est formulé autrement que votre requête. Le sémantique seul peut dériver vers des choses vaguement dans le sujet mais pas ce que vous vouliez dire. Fusionner les deux compense les faiblesses de chacun.
Par-dessus le score fusionné, le classement est rehaussé par trois choses : la température (les souvenirs plus chauds remontent, parce que la récence d’usage est un signal), l’importance (certains souvenirs sont simplement plus lourds) et les liens (un souvenir connecté à d’autres souvenirs pertinents est plus susceptible d’être celui que vous voulez). Le résultat est un classement qui reflète non seulement la similarité textuelle mais aussi à quel point un souvenir est actif et connecté. C’est bien plus proche de la façon dont vous vous rappelez réellement les choses qu’un simple score de similarité.
Le réveil
Tout cela se rejoint au début d’une session dans ce que j’appelle le réveil. Au lieu de commencer chaque conversation comme une page blanche, l’agent effectue un réveil de la mémoire qui fait remonter les souvenirs les plus chauds et les plus pertinents. C’est la différence entre un collègue qui entre en sachant déjà où vous en êtes restés hier et un que vous devez briefer de zéro chaque matin. Le réveil s’appuie sur tout ce qui précède : le modèle de chaleur décide ce qui est actif en ce moment, le rappel hybride décide ce qui est pertinent, et l’agent commence la session déjà orienté. C’est le moment où tout le moteur justifie son existence, parce que c’est le moment où vous sentez l’agent se souvenir de vous.
La phase smarter-brain : liens et rêves
Les pièces ci-dessus formaient le cœur du système de mémoire v2.0. Une phase ultérieure, que je vois comme le travail smarter-brain, a ajouté quelques choses qui font que le cerveau ressemble moins à une base de données et davantage à quelque chose qui réfléchit pendant que vous êtes absent.
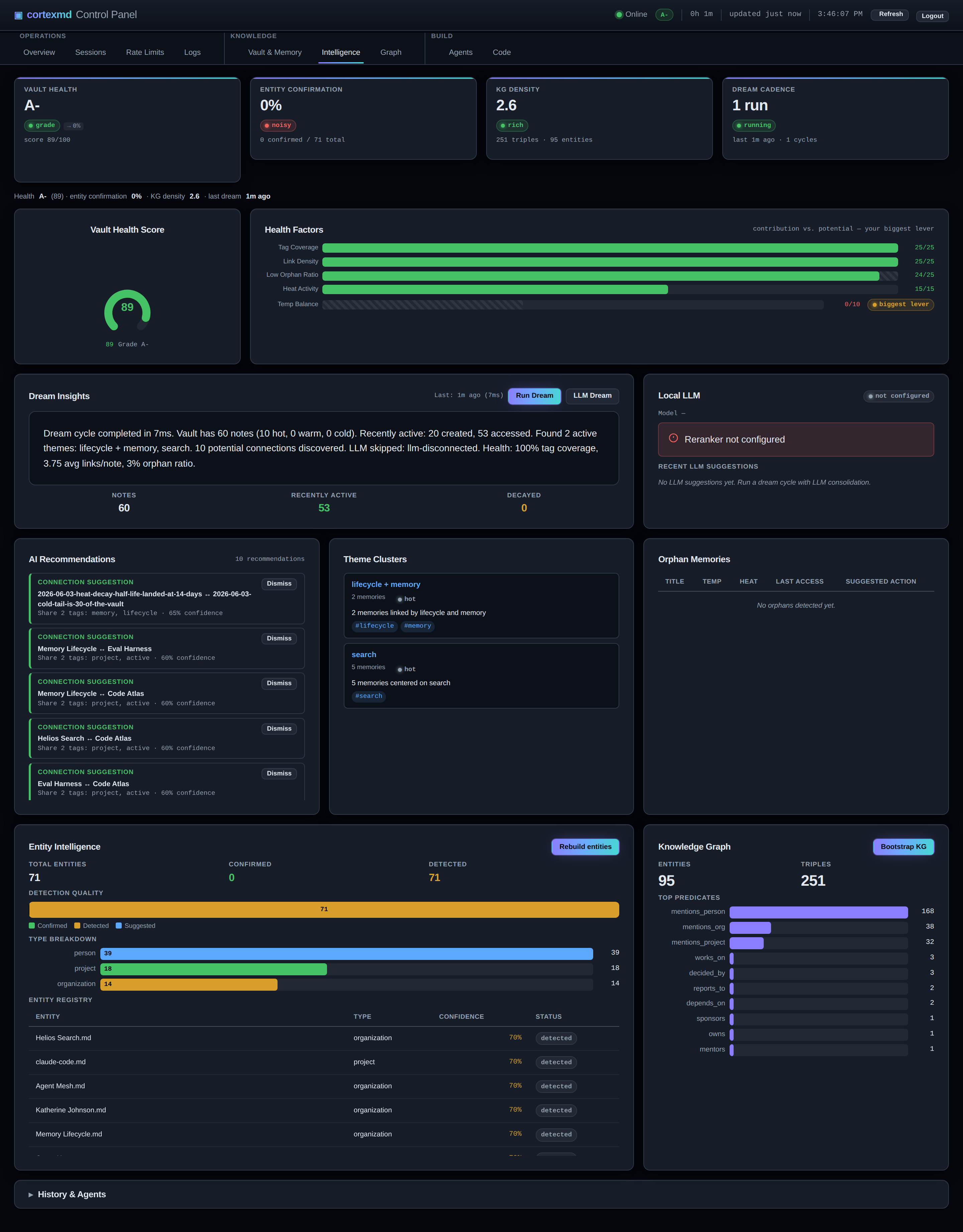
La première, ce sont les liens automatiques du graphe de connaissances. À mesure que les données sont stockées, cortexmd trace de lui-même des liens entre les notes apparentées, au lieu d’attendre que je les câble à la main. Le lien manuel est exactement le genre de tâche administrative qui semble sympa et n’arrive jamais vraiment, donc avoir les connexions qui se forment automatiquement comme effet secondaire du stockage signifie que le signal de liens dans le rappel ne cesse de s’enrichir sans aucun effort de ma part.
La deuxième, c’est le rêve. cortexmd lance une passe de consolidation planifiée, sur un calendrier calme, que j’ai nommée le rêve à cause de ce qu’elle fait et du moment où elle le fait. Elle réconcilie les notes similaires, avec une attention particulière aux plus anciennes, celles qui ont refroidi, et les replie dans des notes de projet. C’est le jardinier d’arrière-plan du cerveau : pendant qu’il ne se passe rien, il parcourt les coins refroidis, remarque que ces trois pensées à moitié finies ne sont en réalité qu’une seule chose, et les range en une note de projet cohérente. Vous réveillez l’agent le lendemain et le cerveau est un peu mieux organisé que vous ne l’aviez laissé, sans que vous n’ayez rien fait.
La troisième, c’est quelque chose que j’ai emprunté tel quel à Obsidian : une vue graphe du coffre, rendue sur un canvas dans le tableau de bord web. Parce que le graphe de connaissances est réel, vous pouvez le regarder. Voir le cerveau comme une constellation de notes liées, avec les grappes denses et les orphelins solitaires étalés devant vous, rend le tout concret d’une manière qu’une liste de lignes ne fait jamais.
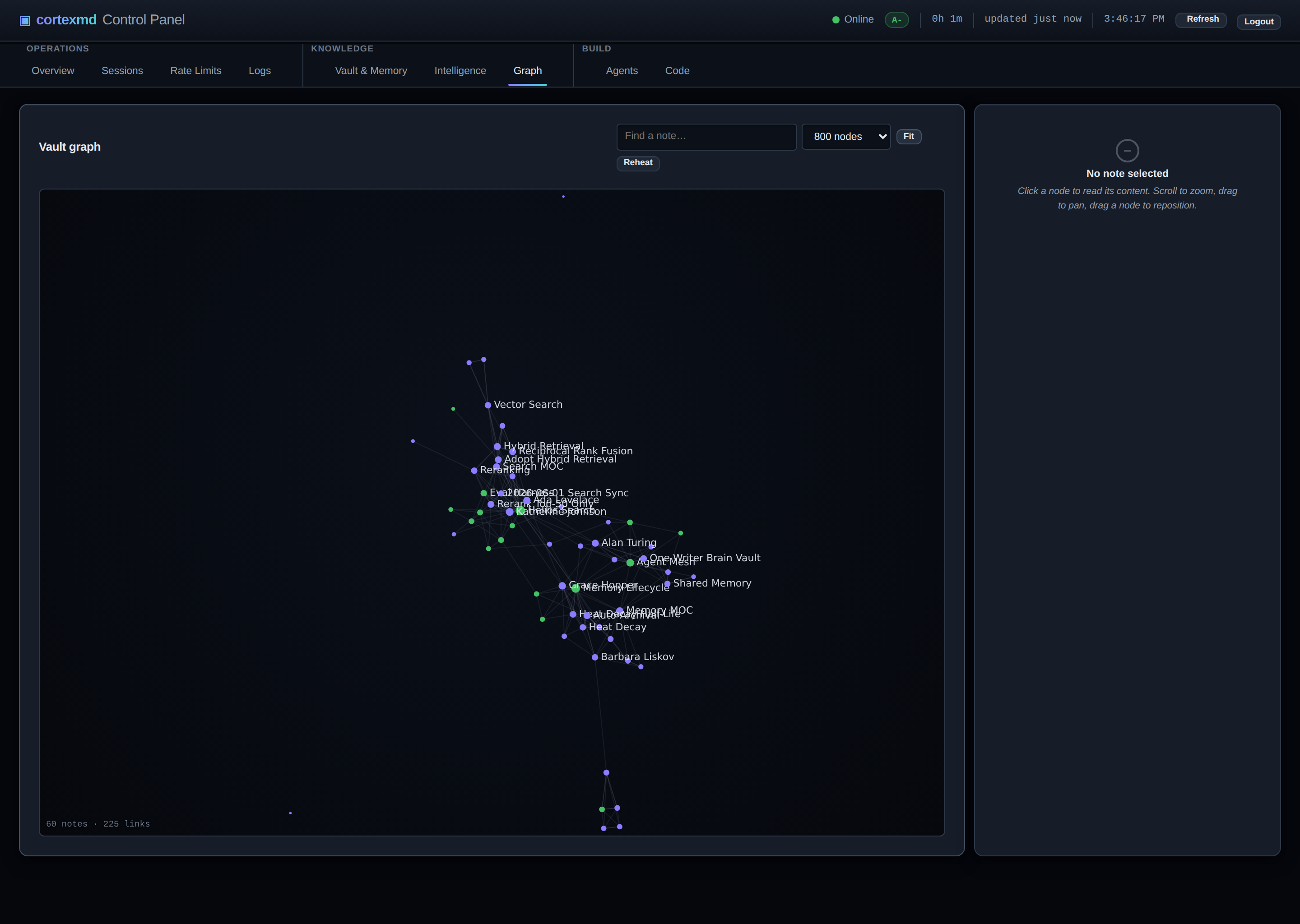
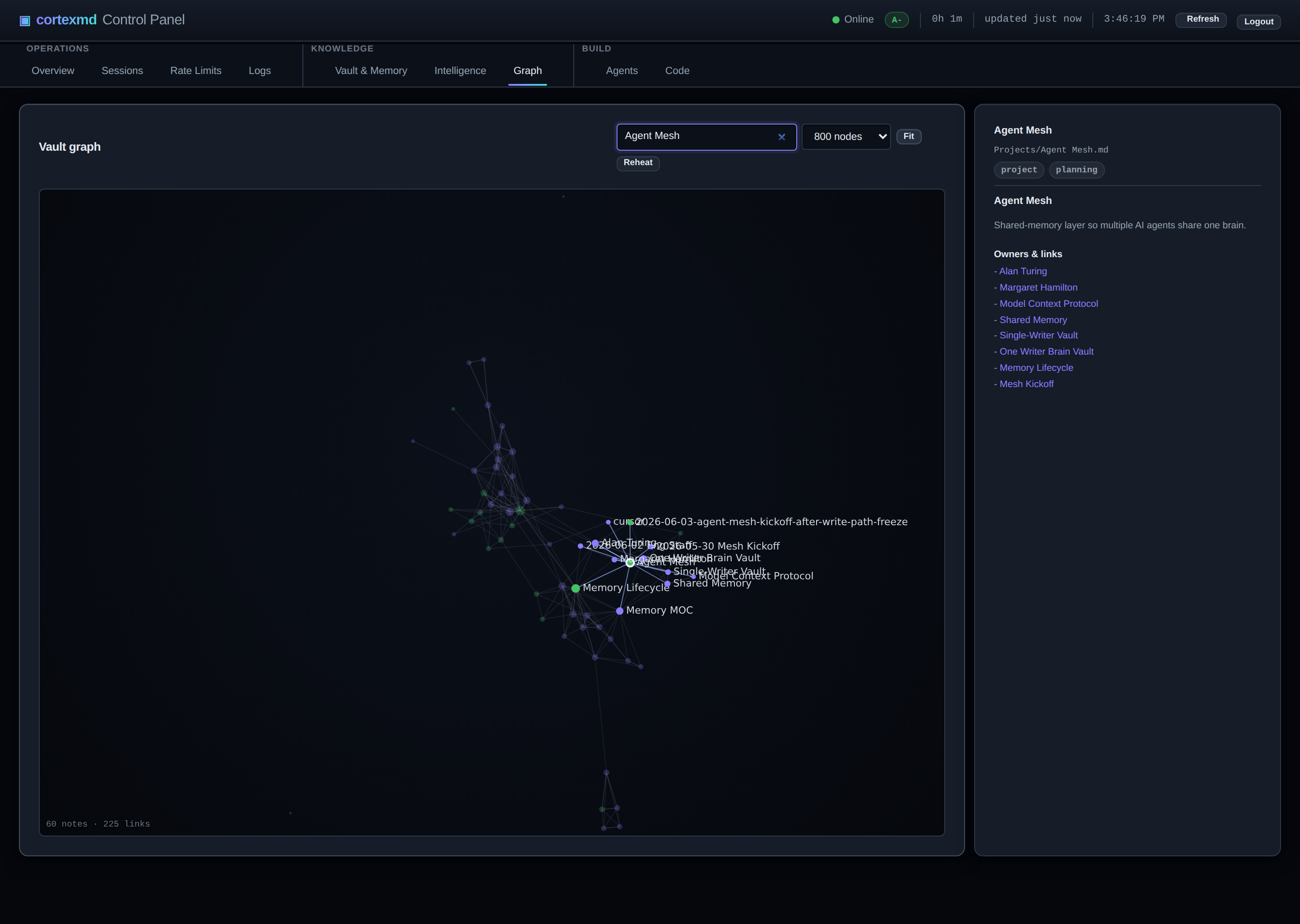
Pourquoi un modèle de chaleur l’emporte
Pour rassembler le tout : la raison pour laquelle un modèle de chaleur bat le fait de tout déverser dans le contexte, c’est que l’attention est la ressource rare, pour un agent exactement comme pour une personne. Un stock plat traite une note d’il y a huit mois et une décision de ce matin comme des égaux, vous fait payer pour les deux à chaque tour, et force l’agent à redécouvrir ce qui compte à chaque fois. Le modèle de chaleur encode ce qui compte comme une propriété des données elles-mêmes, le tient à jour gratuitement par l’usage ordinaire, compresse ce qui a refroidi au lieu de l’accumuler, et fait remonter la tranche active et pertinente au réveil. L’agent porte moins, et ce qu’il porte, c’est ce qu’il faut.
Voilà pour l’oubli. L’autre moitié du problème d’origine, l’agent qui brûle des tokens à relire du code qu’il a déjà vu, demande un mécanisme complètement différent. C’est un indexeur Rust et une base de données de symboles, et c’est le sujet de la troisième partie : le tueur de tokens.
cortexmd est en pré-alpha et sous licence MIT. Le code, y compris le moteur de mémoire décrit ici, vit sur la page du projet et sur GitHub à github.com/Leicas/cortexmd. Les noms et la configuration sont encore mouvants, alors traitez les détails comme un instantané plutôt que comme un contrat.
Série
Ceci est la deuxième partie d’une série de quatre billets sur cortexmd :
- Donner un second cerveau à un agent IA
- Le moteur de mémoire : chaleur, déclin et rêves (vous êtes ici)
- Le tueur de tokens : naviguer dans le code sans le lire
- Ouvrir le cerveau : le modèle brain-vault
Antoine Weill--Duflos
Responsable Technologie et Applications
Je m’intéresse à l’haptique, la mécatronique, la micro-robotique…