The Token Killer: Navigating Code Without Reading It
In part two I wrote about the half of cortexmd that fights forgetting: the memory engine, with its heat and decay and its nightly dream. This post is about the other half, the half that fights waste.
Here is the problem. When you ask an AI agent to work on a real codebase, the default move is to read files. The agent opens a file, the whole thing lands in its context, and now you are paying for every line of it. Most of those lines are noise for the task at hand. You wanted to know what one function does and who calls it, and instead you bought a thousand-line file plus imports plus three helper modules it pulled in to be safe. Do that a few times and the context window is full of code the agent will never use, the signal is buried, and the bill is real.
The fix is to stop reading code and start querying it.
A repo is a graph, not a pile of text
The insight is old and boring and correct: source code is not really a flat pile of text. It is a graph of symbols. Functions, methods, types, and the edges between them, who calls whom. An IDE knows this. “Go to definition” and “find all references” do not read your files top to bottom every time you click. They consult an index. cortexmd gives an agent the same thing.
The indexer is a Rust binary (cortexmd-cli, the same binary that ships the CLI client and the session hooks I will get to). It walks a repo, parses each file with tree-sitter, and writes the result into a SQLite symbol database. For every symbol it records the name, the kind (function, method, type, and so on), the signature, the docstring if there is one, the file range, and, crucially, the call graph: callers and callees. tree-sitter is the right tool here because it is fast, it is incremental, and it speaks a lot of languages, so the same indexing pass works across a polyglot repo instead of needing one bespoke parser per toolchain.
Once that database exists, the agent never has to open a file just to orient itself.
The code-nav tools
The index is exposed to MCP clients as a set of cheap tools. Each one answers a specific question that an agent actually asks while working:
- symbol search: find symbols by name, signature, or docstring text. The entry point into everything else.
- file outline: the shape of a file (its symbols and their signatures) without the bodies. You get the table of contents instead of the book.
- get one symbol: pull the body of exactly one symbol when you have decided you need it, and nothing else.
- callers and callees: walk the call graph in either direction. Who calls this, what does this call.
- change impact: the transitive answer to “if I change this, who breaks?” This is the one I reach for most before touching anything load-bearing.
- call chain: the path from one symbol to another, so you can see how A actually reaches Z.
- find dead code: symbols nothing resolves to.
- find import cycles: where the module graph loops back on itself.
- find semantic duplicates: copy-paste detection, the near-identical bodies that drifted apart.
The pattern across all of them is the same. The agent narrows before it reads. Search to find the symbol, outline to see the neighbourhood, callers and change-impact to understand the blast radius, and only then, if it truly needs the body, get one symbol. Most tasks never need a full file at all.
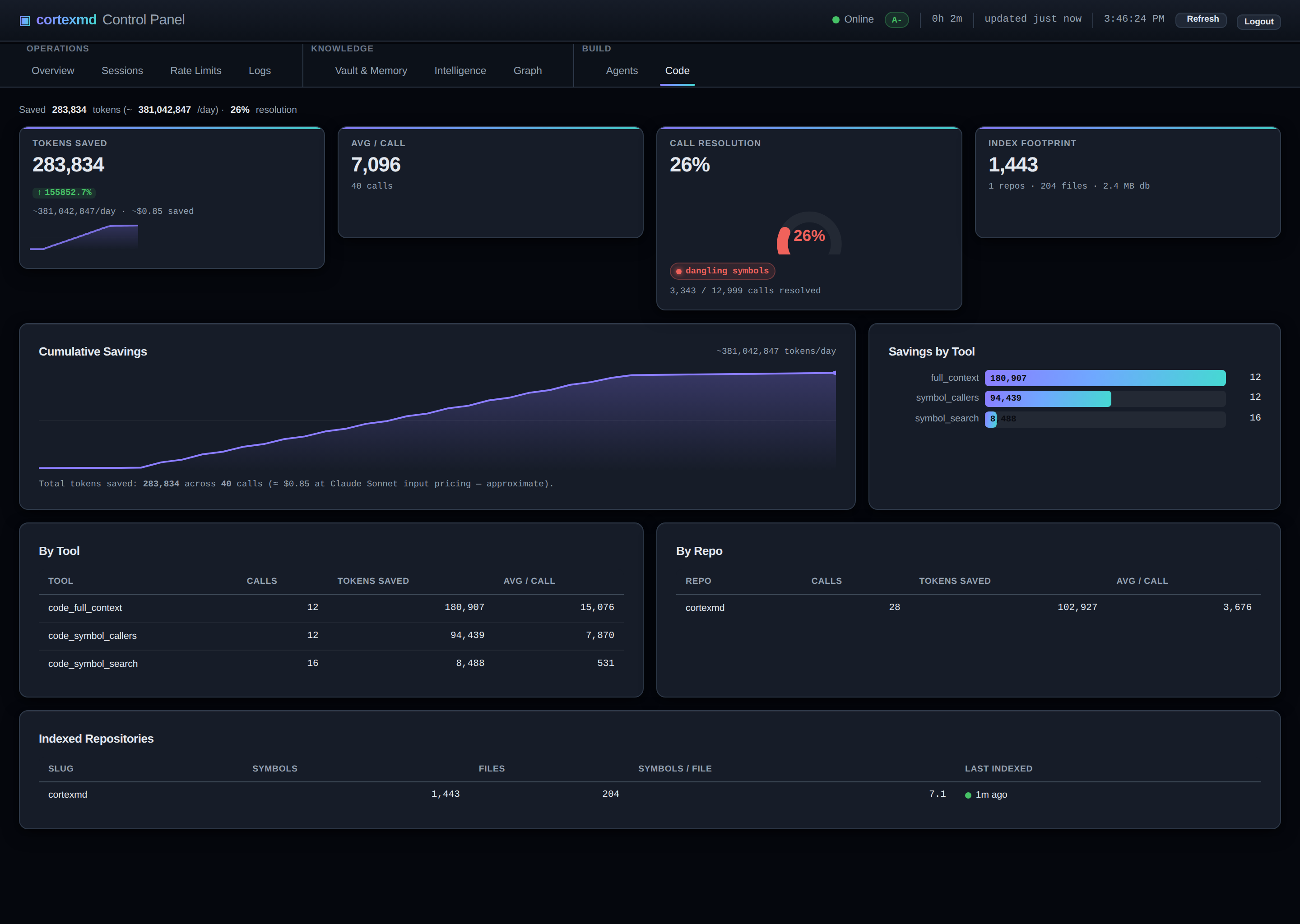
Roughly 60 tokens per result
Here is the design goal that drove the whole thing. A code-nav lookup is meant to cost roughly 60 tokens per result. Reading a whole file costs thousands. So querying the index is meant to be many times cheaper than reading, for the same useful answer.
I want to be honest about what that number is and is not. It is a target I designed toward, not a benchmark I am quoting at you. The exact cost depends on the symbol, the language, how much docstring there is. But the shape of it is the entire point: a result is a compact record (name, kind, signature, a range, some edges), not a slab of source. When the unit of work is a 60-token fact instead of a 2,000-token file, an agent can ask twenty questions for the price of one read, and the context window stays full of answers instead of haystack.
It also reads better for the model. A clean list of callers is easier to reason over than the same information smeared across five files the agent had to load to reconstruct it.
Catching the old habit
There is a catch with giving an agent better tools: it has to remember to use them. The muscle memory of “investigate the code” is grep, cat, head, tail. Those habits are deep, and an agent will happily fall back to them and start hauling files into context the moment you stop watching.
So cortexmd ships an opt-in shell hook. When it is on and you are working in an indexed repo, it rewrites those commands into their cheap code-nav equivalents. A grep for a symbol becomes a symbol search. A cat of a file becomes a file outline. The agent thinks it is doing the old thing, and the index quietly answers instead. It is opt-in on purpose, because rewriting someone’s shell commands is exactly the kind of magic you want to consent to rather than discover, and because the rewrite only makes sense on a repo that is actually indexed.
The nice property is that it meets the agent where its habits already are. You do not have to retrain the reflex, you just intercept it.
Dogfooding on its own source
I did not test this on a toy. cortexmd is a polyglot monorepo (TypeScript on one side, Rust on the other, more on that in part four), and I pointed the indexer at the project’s own source and worked on it through its own code-nav tools. That is the test that matters. When you are changing the indexer while navigating with the indexer, the rough edges find you fast. “Change impact says nothing breaks, so why did that break” is a very motivating sentence to read in your own logs.
Dogfooding is also where the two halves of cortexmd meet. The code index tells the agent what the code is right now. The memory engine from part two tells it why the code is the way it is, the decisions and the dead ends that no symbol database will ever record. Structure plus history. One is queried, one is recalled, and together they are most of what I want a collaborator to have.
This is still pre-alpha, so the exact tool names and config will move around. The idea underneath is stable: navigate code by querying an index, not by reading files, and pay 60 tokens for a fact instead of thousands for a haystack.
In part four I get to the part that turned a private homelab tool into something I could put on the internet: why a tool tuned entirely to my own setup could not be shared as-is, the brain-vault redesign that generalised it, and why I open-sourced it.
The project page is here, and the code is at github.com/Leicas/cortexmd.
Series
- Giving an AI Agent a Second Brain
- The Memory Engine: Heat, Decay, and Dreams
- The Token Killer: Navigating Code Without Reading It (you are here)
- Open-Sourcing the Brain: the Brain-Vault Model
Antoine Weill--Duflos
Head of Technology and Applications
My research interests include haptic, mechatronics, micro-robotic and hci.