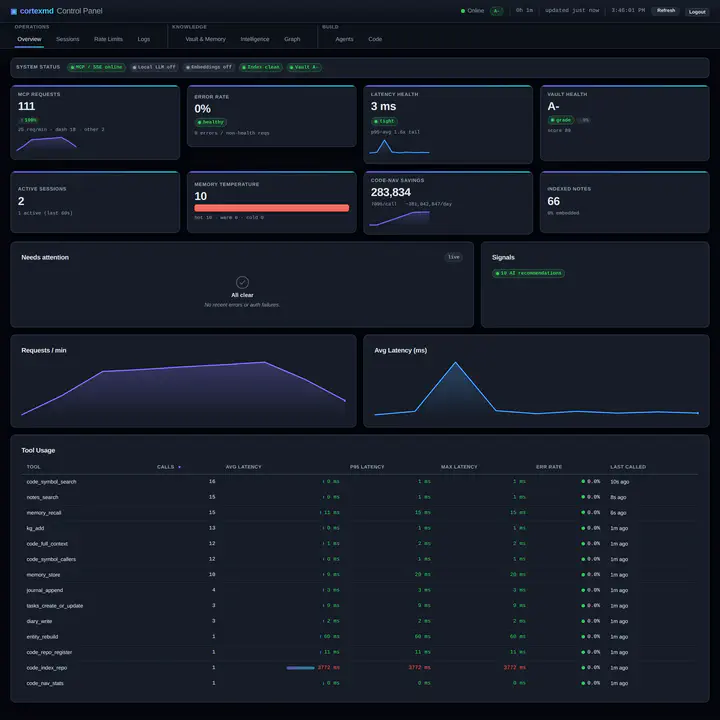
 Le panneau de contrôle de cortexmd, sur la démonstration autonome du projet : les notes et les chiffres sont des données d’exemple seedées, pas mon vrai coffre.
Le panneau de contrôle de cortexmd, sur la démonstration autonome du projet : les notes et les chiffres sont des données d’exemple seedées, pas mon vrai coffre.
cortexmd est un cerveau de mémoire à long terme et de navigation de code pour agents IA, exposé via le Model Context Protocol. Tout a commencé par un projet privé sur mon homelab appelé obsidian-mcp, un serveur qui permettait à Claude de lire, chercher et écrire des notes dans mon coffre Obsidian. Je l’ai construit pour moi, puis je l’ai nettoyé pour le partager.
Il fait deux choses.
La première, c’est la mémoire. Les agents oublient tout d’une session à l’autre. cortexmd leur offre un endroit où déposer ce qu’ils apprennent : des mémoires auto-catégorisées en types comme observation, décision, intuition et plan, avec un cycle de vie thermique où lire une mémoire la réchauffe et l’inactivité la refroidit. Le rappel est hybride, fusionnant la recherche plein texte et la recherche sémantique, amplifié par la température et les liens. Au début d’une session, l’agent effectue un réveil qui fait remonter les mémoires les plus chaudes et les plus pertinentes, pour reprendre là où il s’était arrêté.
La seconde, c’est la navigation de code. Un indexeur en Rust parcourt un dépôt, l’analyse avec tree-sitter et construit une base de données de symboles en SQLite qui enregistre, pour chaque symbole, son nom, son type, sa signature, sa docstring, sa plage dans le fichier et son graphe d’appels. Cet index est exposé sous forme d’outils MCP peu coûteux : recherche de symboles, plan de fichier, appelants et appelés, impact des changements, chaîne d’appels, code mort, cycles d’import et doublons issus de copier-coller. L’objectif de conception est qu’un agent navigue dans le code en interrogeant l’index, à environ 60 jetons par résultat, plutôt qu’en lisant des fichiers entiers. Un hook shell optionnel réécrit des commandes comme grep et cat sur un dépôt indexé en l’appel de navigation de code équivalent.
L’élément qui l’a rendu publiable, c’est le modèle de coffre-cerveau (brain-vault). cortexmd possède un coffre-cerveau distinct qui est la seule chose dans laquelle il écrit. Vos propres coffres sont attachés en tant que sources en lecture seule, indexés pour la recherche et la navigation de code, jamais modifiés, avec une liste d’autorisation par refus par défaut pour que les sous-arbres privés restent à l’écart. Les données circulent dans un seul sens, donc il n’y a aucun fichier mutable partagé et aucune course à la fusion.
SOURCE_VAULTS[] (read-only, opt-in, allowlisted)
┌───────────┐ ┌───────────┐ ┌───────────┐
│ notes/ │ │ code/ │ │ docs/ │
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ index (one-way, read) │
└──────────────┼──────────────┘
▼
┌──────────────────┐
│ cortexmd │ <- sole writer
│ (MCP server) │
└────────┬─────────┘
│ writes
▼
┌──────────────────┐
│ BRAIN_VAULT │ memories · journal · diaries
│ (own dir, not │ tasks · KG notes · code-repos.json
│ your vault) │
└──────────────────┘
Il fonctionne selon deux modes : un mode local-stdio sans Docker, sans authentification et sans réseau, recommandé pour une seule personne ; et un mode HTTP auto-hébergé avec authentification pour les configurations multi-clients. Le dépôt est un monorepo polyglotte, un serveur MCP en TypeScript et un binaire Rust unique, maintenus cohérents par un contrat partagé et une vérification de parité en CI.
cortexmd est en pré-alpha et sous licence MIT. Les API et les noms de configuration sont encore susceptibles de changer.
L’histoire complète est racontée dans une série de quatre billets de blog. Commencez par Donner un second cerveau à un agent IA.
Antoine Weill--Duflos
Responsable Technologie et Applications
Je m’intéresse à l’haptique, la mécatronique, la micro-robotique…