The Memory Engine: Heat, Decay, and Dreams
In part one I described two problems that kept biting me while working with AI agents. The first was that they forget everything between sessions. The second was that they burn tokens re-reading code they have already seen. This post is about the first problem, and the part of cortexmd I am most attached to: the memory engine. The overall approach is inspired by mempalace, a memory-palace project for AI agents; what follows is how cortexmd builds its own version.
The naive fix for forgetting is to dump everything into context. Keep a big file of notes, paste it in at the start of every session, and hope the agent reads it. I tried versions of that, and it falls apart fast. The file grows without bound. Old, stale facts sit next to the one thing that actually matters today, with equal weight. You pay for the whole pile on every turn, and the signal you care about gets buried in noise you have long since stopped caring about. A human memory does not work like that, and it should not. So the design goal was simple to state and harder to build: the agent should remember the way a person does, where the things you use stay sharp and the things you stop touching fade.
Eight kinds of memory
When an agent stores something, cortexmd does not treat it as an undifferentiated blob of text. Each memory is auto-categorised into one of eight kinds: observation, decision, insight, conversation, fact, preference, plan, and reflection. The distinction matters because these things behave differently over time and want to be retrieved differently. A preference (I always want British spelling, I hate em dashes) is a long-lived fact about how I work, and it should keep surfacing. A conversation snippet is contextual and mostly useful soon after it happened. A decision is something you want to be able to find again months later when you ask yourself why on earth you did that. Tagging the kind up front gives the rest of the system something to reason with, instead of forcing every later step to guess from raw text.
Heat: hot, warm, cold
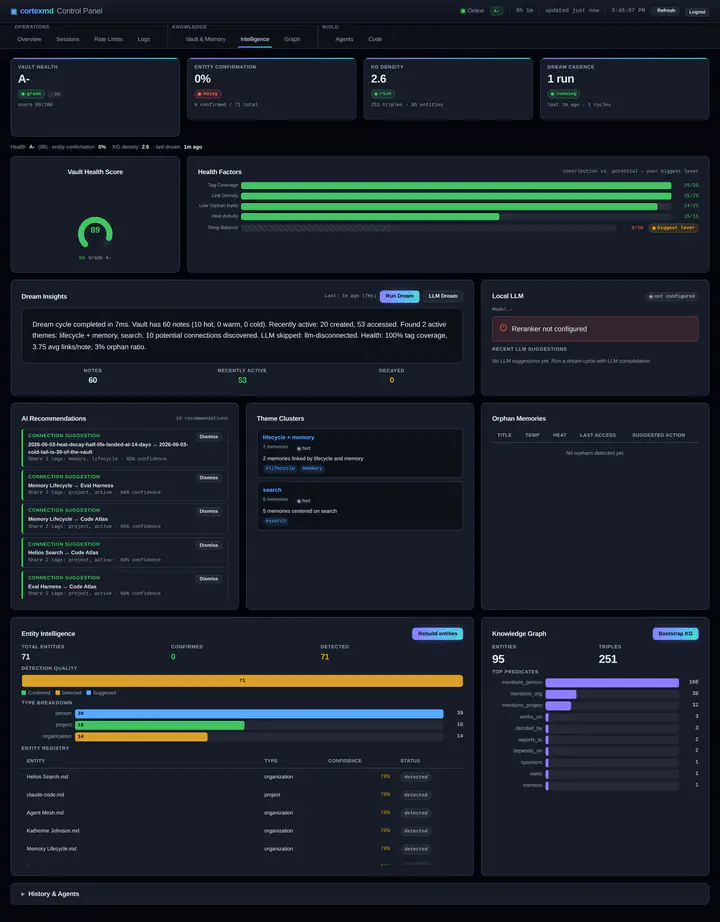
The core idea is that every memory has a temperature, and temperature decays. A fresh or recently used memory is hot. Leave it untouched and it cools to warm, then after roughly a month of inactivity it drifts to cold, and colder memories are eventually archived rather than kept in the front of the agent’s mind.
The crucial detail is promote-on-access: reading a memory heats it back up. This is the whole trick. You do not have to manually curate what is important. Importance is revealed by use. The memories you and the agent keep reaching for stay hot precisely because you keep reaching for them, and the ones you never touch sink on their own. It is the same instinct as a least-recently-used cache, except the thing being cached is the agent’s sense of what currently matters, and the eviction is graceful: cold and archived, not deleted.
Why bother with all this instead of one flat store? Because temperature gives recall a prior. When the agent goes looking for something, it does not face a flat sea of equally plausible notes. It has a built-in sense of what has been live lately, and that signal costs nothing extra to maintain because it falls out of normal use.
Consolidation: tidying the cold drawer
Letting memories cool is only half the story. If you simply let cold memories pile up, you end up with a drawer full of near-duplicate scraps: five slightly different notes about the same long-finished task, each a little stale, none worth reading on its own. So cortexmd consolidates. Related cold memories get folded together into summaries, so the gist survives in one coherent place while the redundant fragments stop cluttering things. The detail is not thrown away carelessly, it is compressed into something you would actually want to read later. Cooling decides what is no longer urgent; consolidation decides what to do with it.
Hybrid recall
Storing memory well is pointless if you cannot get it back. Recall in cortexmd is hybrid. It runs a lexical full-text search (the keyword match, good at exact terms and names) and fuses it with a semantic search over embeddings (the meaning match, good when you remember the idea but not the words). Lexical alone misses anything phrased differently from your query. Semantic alone can drift toward things that are vaguely on-topic but not what you meant. Fusing the two covers for the weaknesses of each.
On top of the fused score, the ranking is boosted by three things: temperature (hotter memories rank higher, because recency of use is a signal), importance (some memories are simply weightier), and links (a memory connected to other relevant memories is more likely to be the one you want). The result is a ranking that reflects not just textual similarity but how live and how connected a memory is. That is much closer to how you actually recall things than a plain similarity score.
Waking up
All of this comes together at the start of a session in what I call the wakeup. Instead of beginning every conversation as a blank slate, the agent does a memory wakeup that surfaces the hottest, most relevant memories. It is the difference between a colleague who walks in already knowing where you left off yesterday and one you have to brief from scratch every single morning. The wakeup leans on everything above: the heat model decides what is currently live, hybrid recall decides what is relevant, and the agent starts the session already oriented. This is the moment where the whole engine earns its keep, because it is the moment you feel the agent remembering you.
The smarter-brain round: links and dreams
The pieces above were the heart of the v2.0 memory system. A later round, which I think of as the smarter-brain work, added a few things that make the brain feel less like a database and more like something that thinks while you are away.
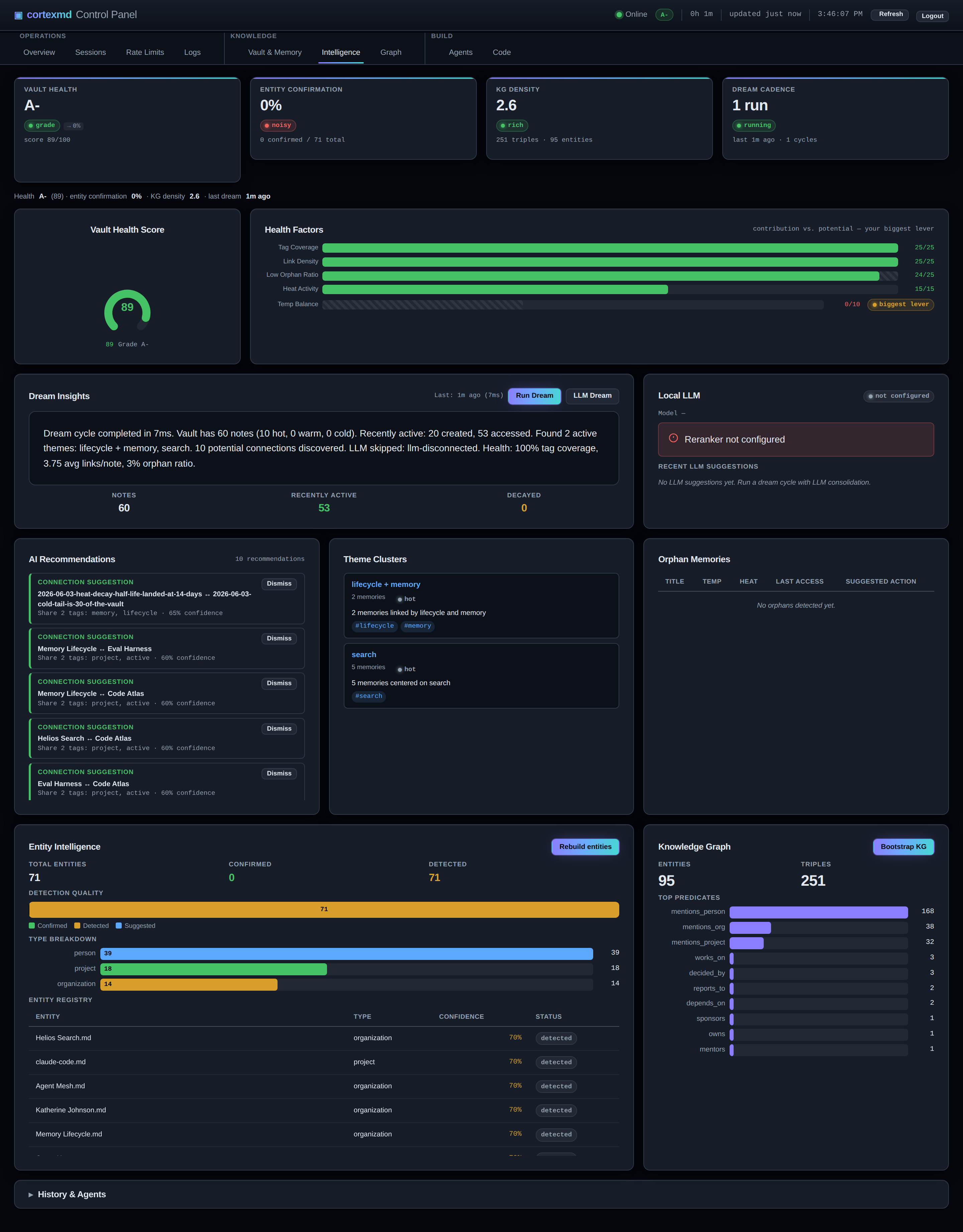
The first is automatic knowledge-graph links. As data is stored, cortexmd draws links between related notes on its own, instead of waiting for me to wire them up by hand. Manual linking is exactly the kind of bookkeeping that sounds nice and never actually happens, so having the connections form automatically as a side effect of storing things means the link signal in recall keeps getting richer without any effort from me.
The second is the dream. cortexmd runs a scheduled consolidation pass, on a quiet schedule, that I named the dream because of what it does and when it does it. It reconciles similar notes, with particular attention to older, cooled-down ones, and folds them into project notes. It is the background gardener of the brain: while nothing is happening, it walks through the cooled corners, notices that these three half-finished thoughts are really one thing, and tidies them into a coherent project note. You wake the agent up the next day and the brain is a little more organised than you left it, without you having done anything.
The third is something I borrowed straight from Obsidian: a vault graph view, rendered on a canvas in the web dashboard. Because the knowledge graph is real, you can look at it. Seeing the brain as a constellation of linked notes, with the dense clusters and the lonely orphans laid out in front of you, makes the whole thing feel concrete in a way a list of rows never does.
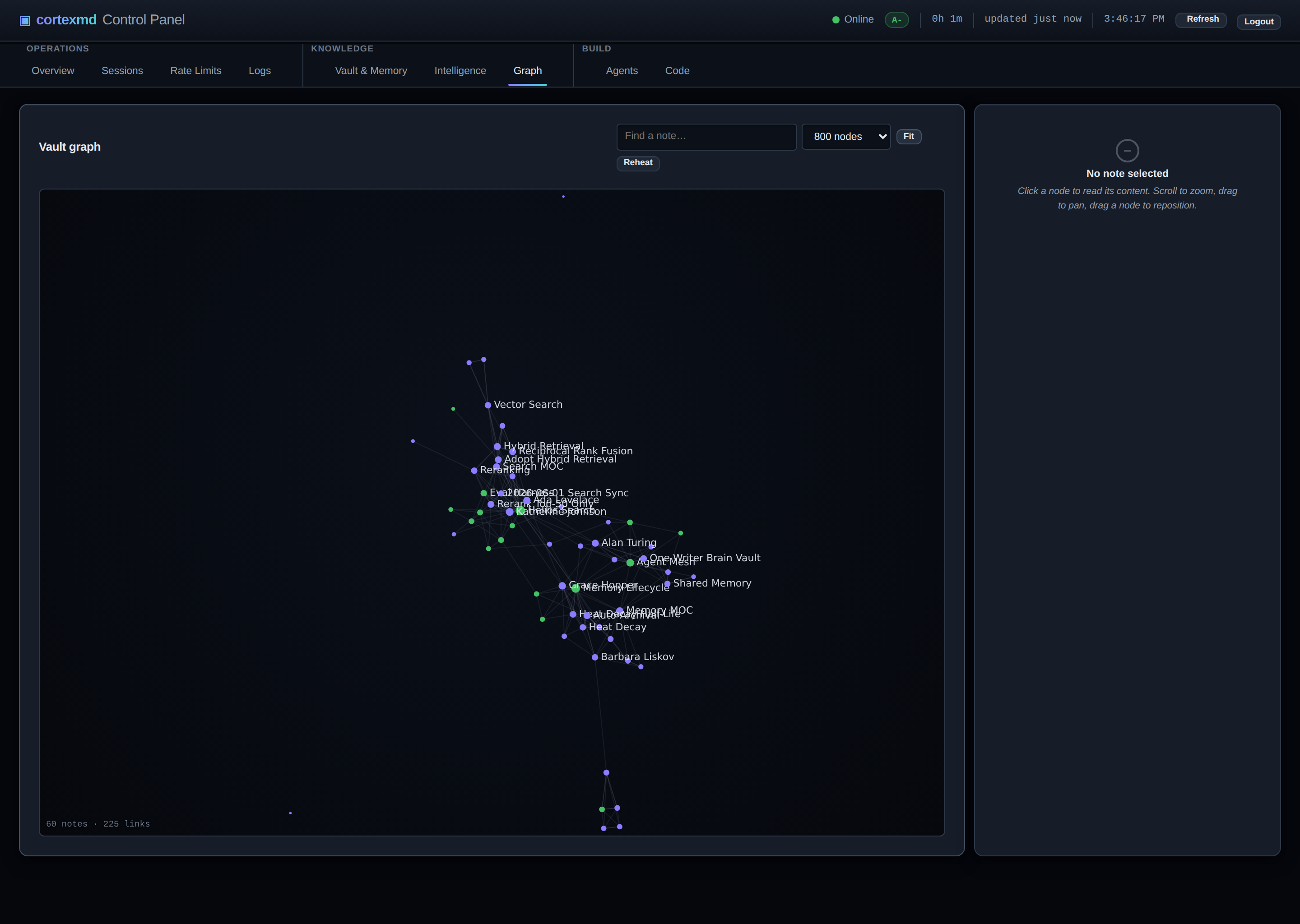
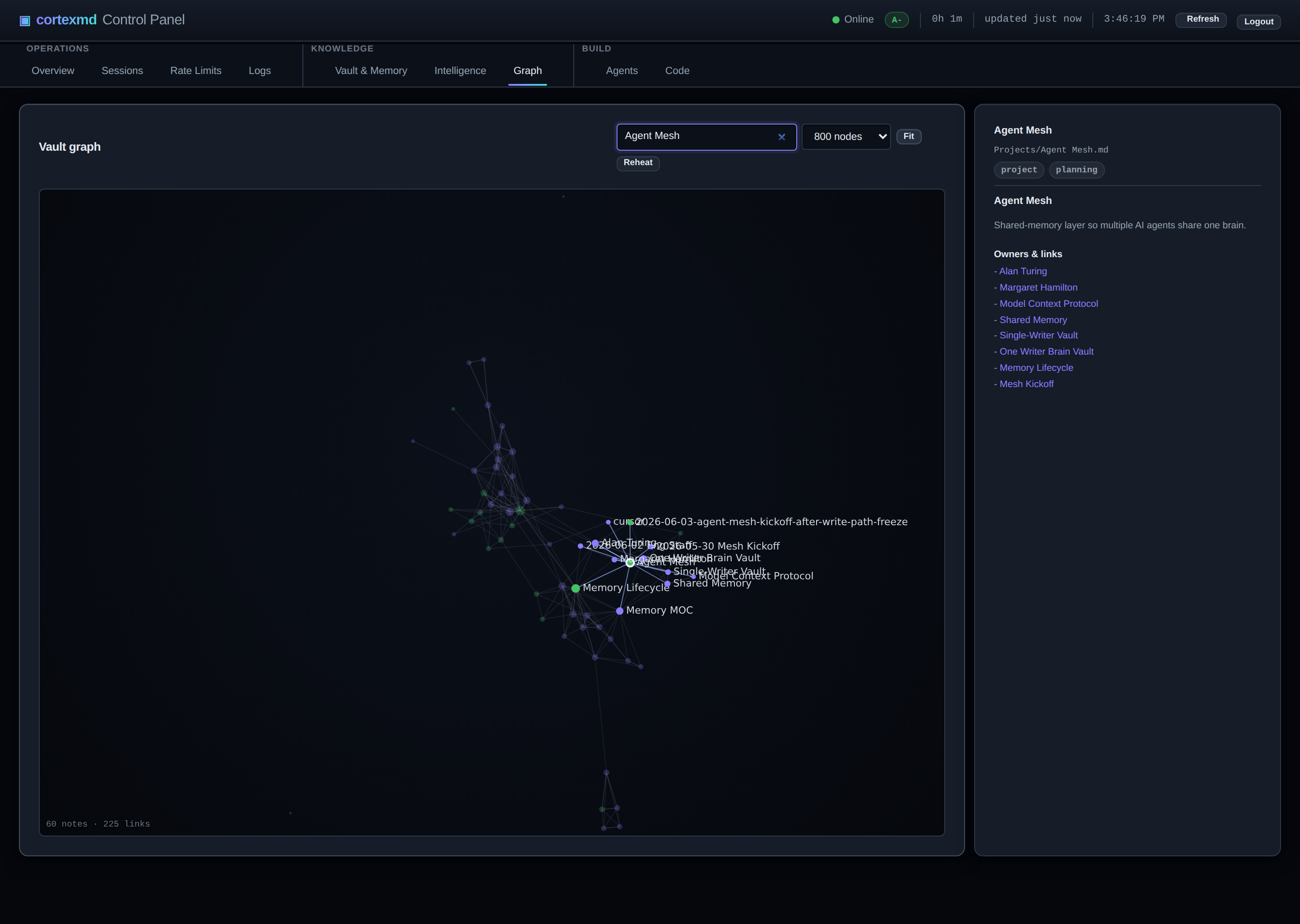
Why a heat model wins
Pulling it together: the reason a heat model beats dumping everything into context is that attention is the scarce resource, for an agent exactly as for a person. A flat store treats a note from eight months ago and a decision from this morning as equals, makes you pay for both on every turn, and forces the agent to rediscover what matters each time. The heat model encodes what matters as a property of the data itself, keeps it current for free through ordinary use, compresses what has gone cold instead of hoarding it, and surfaces the live, relevant slice at wakeup. The agent carries less, and what it carries is the right stuff.
That handles forgetting. The other half of the original problem, the agent burning tokens re-reading code it has already seen, needs a completely different mechanism. That is a Rust indexer and a symbol database, and it is the subject of part three: The Token Killer.
cortexmd is pre-alpha and MIT licensed. The code, including the memory engine described here, lives on the project page and on GitHub at github.com/Leicas/cortexmd. Names and config are still in flux, so treat the specifics as a snapshot rather than a contract.
Series
This is part two of a four-part series on cortexmd:
- Giving an AI Agent a Second Brain
- The Memory Engine: Heat, Decay, and Dreams (you are here)
- The Token Killer: Navigating Code Without Reading It
- Open-Sourcing the Brain: the Brain-Vault Model
Antoine Weill--Duflos
Head of Technology and Applications
My research interests include haptic, mechatronics, micro-robotic and hci.